|
I am a Research Scientist at Amazon Frontier AI & Robotics (FAR). Previously, I was a Research Scientist at ByteDance / TikTok. I received my Ph.D. degree from Computer Science department at Johns Hopkins University, advised by Bloomberg Distinguished Professor Dr. Alan Yuille. I am a member of Computational Cognition, Vision, and Learning. Before that, I obtained B.S. in Computer Science at Peking University in 2018. |

|
|
|
My research lies in generative modeling, multi-modality, and machine perception. For full list of my publications, please refer to my Google Scholar for full publications as I may be too lazy to update my personal website. |

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
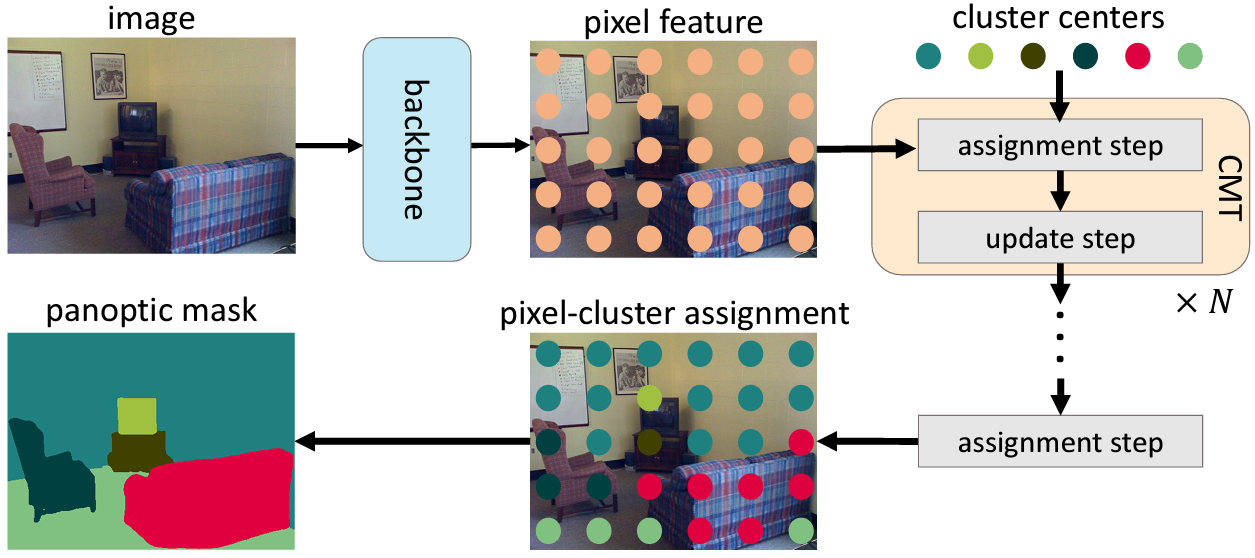
|
|
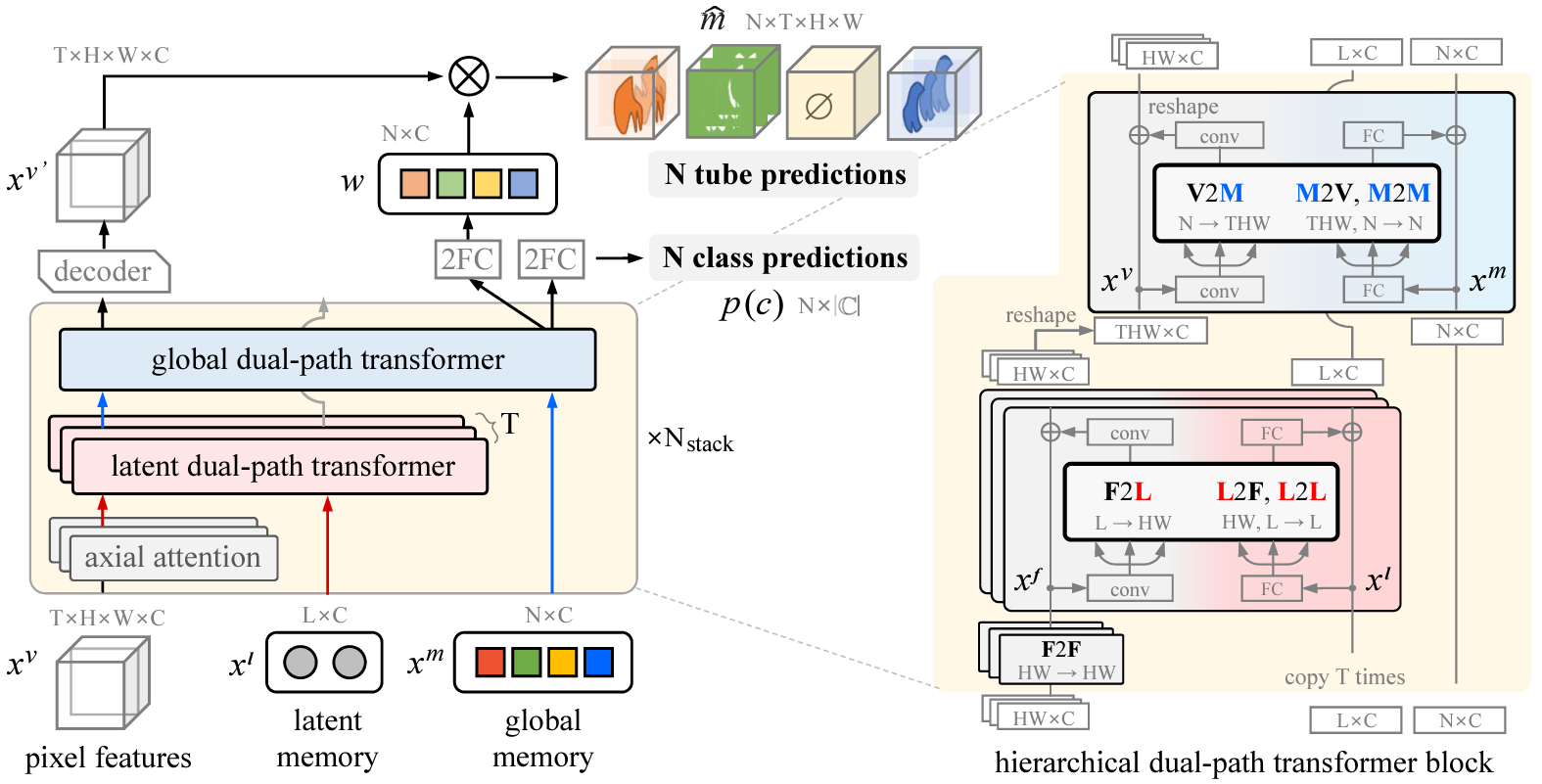
|
|
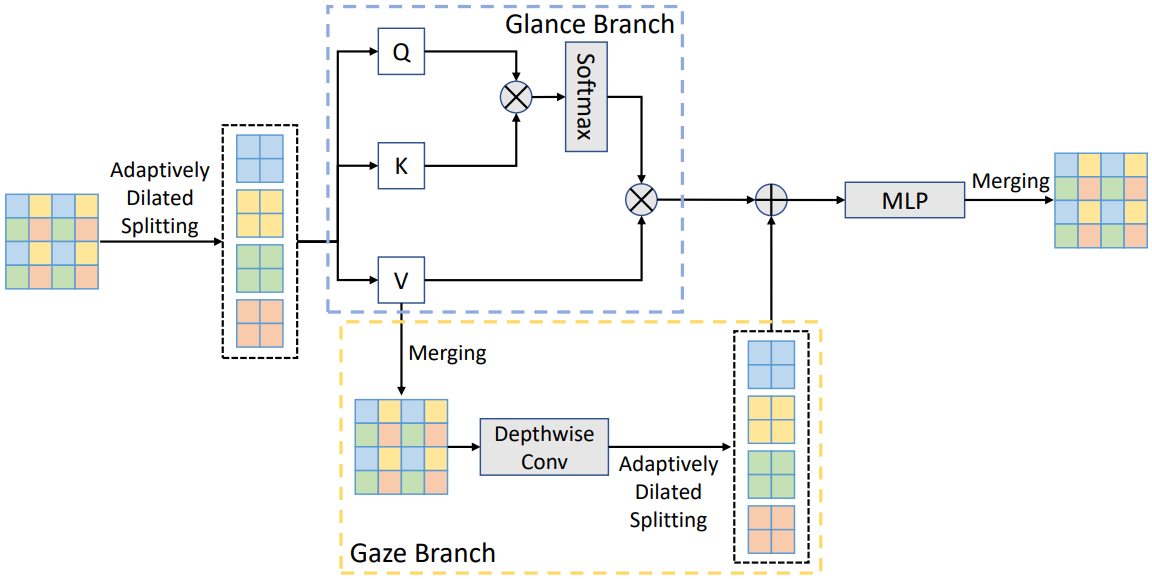
|
|

|
|

|
|
|
|
|

|
|
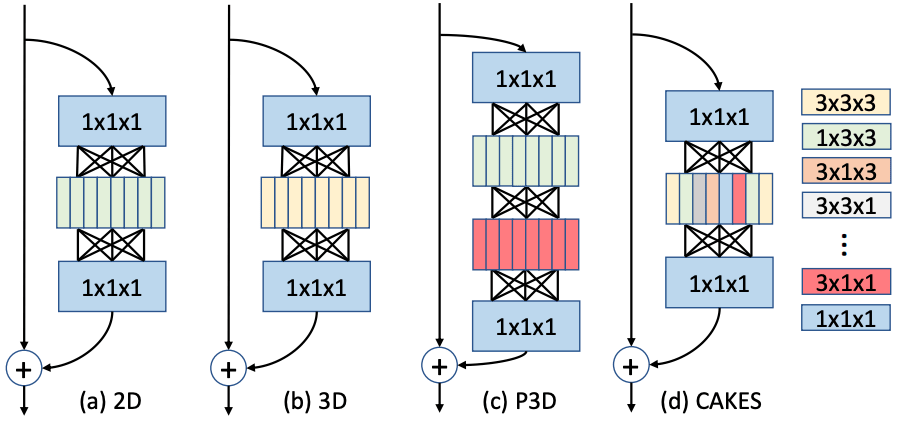
|
|
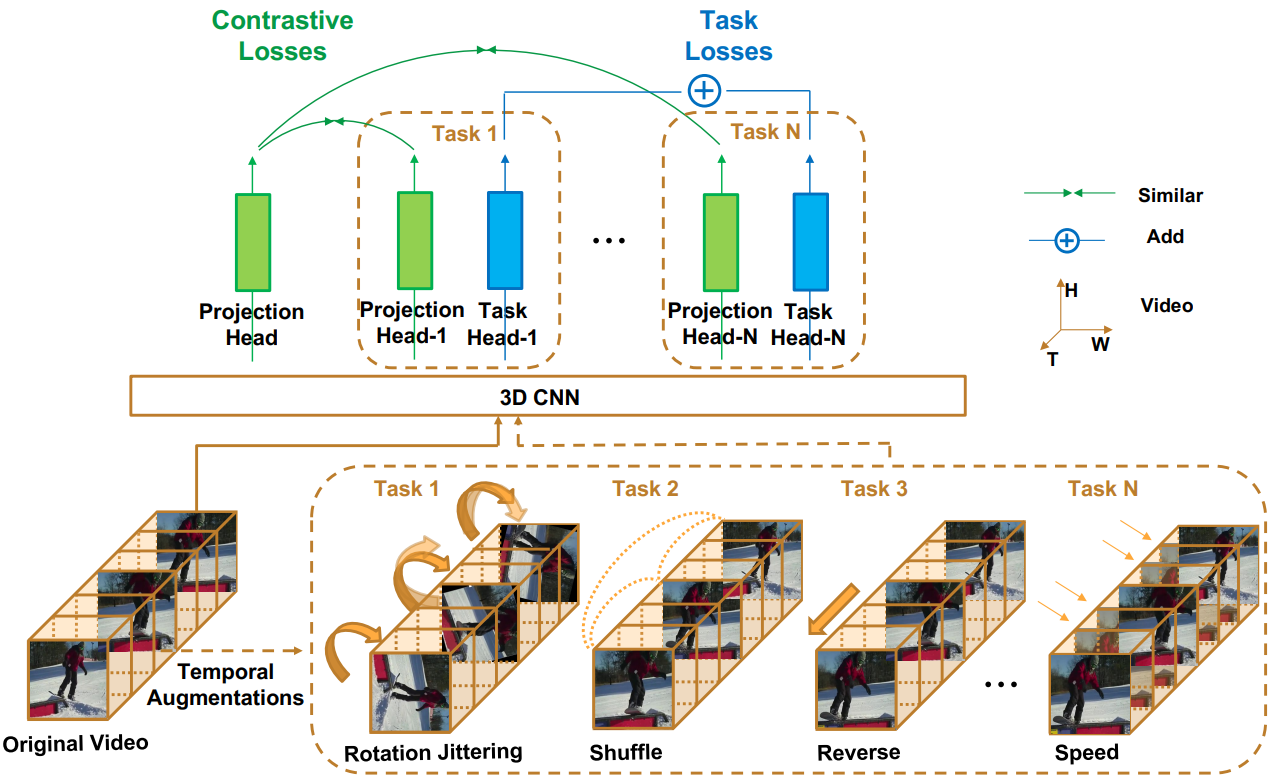
|
|
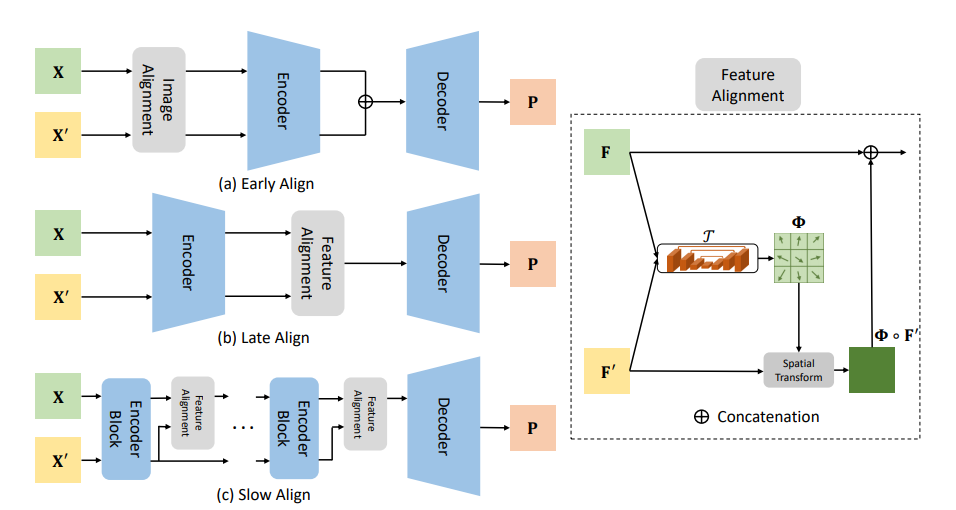
|
|
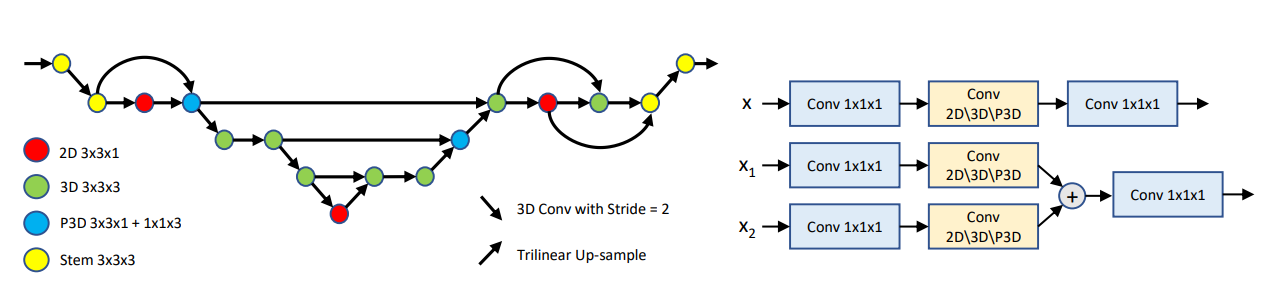
|
|
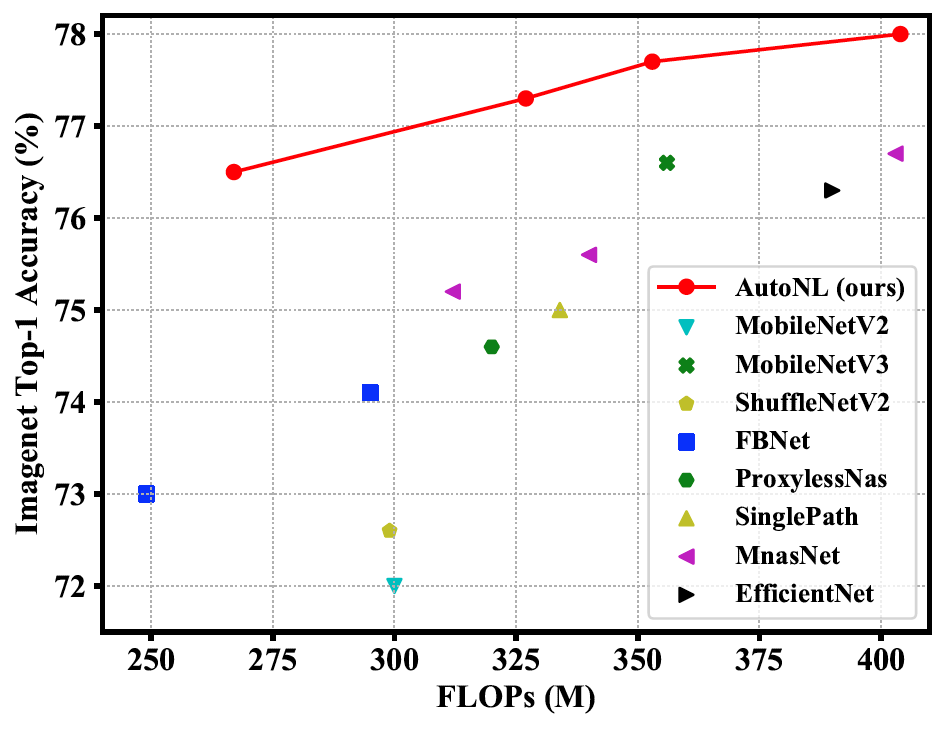
|
|
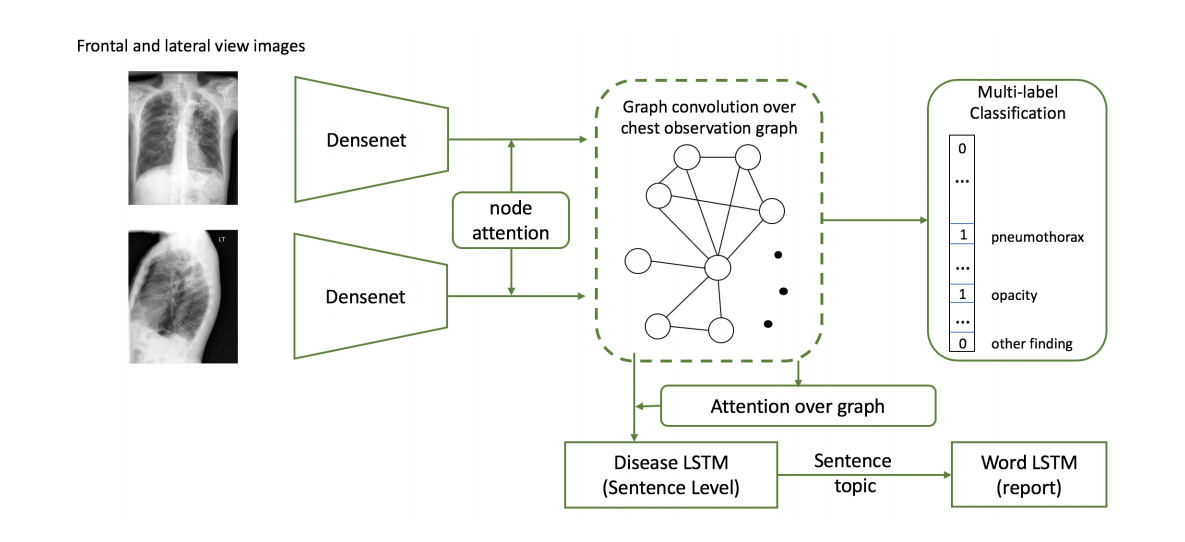
|
|
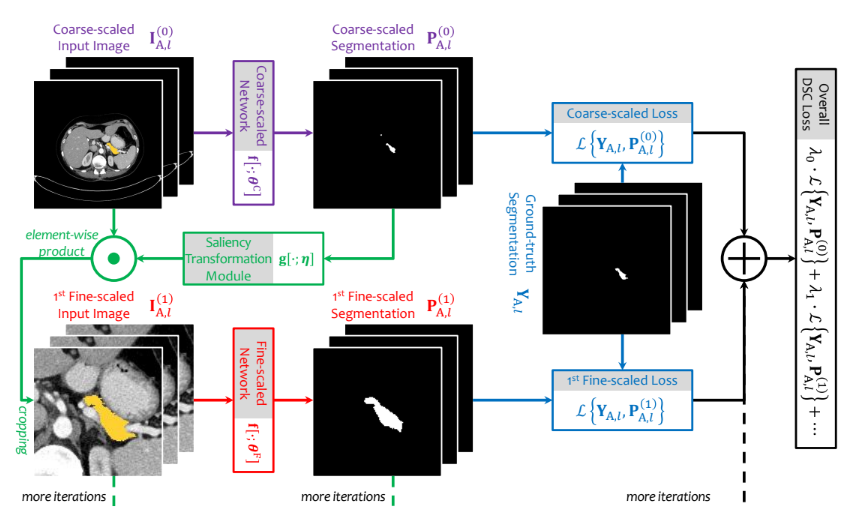
|
|
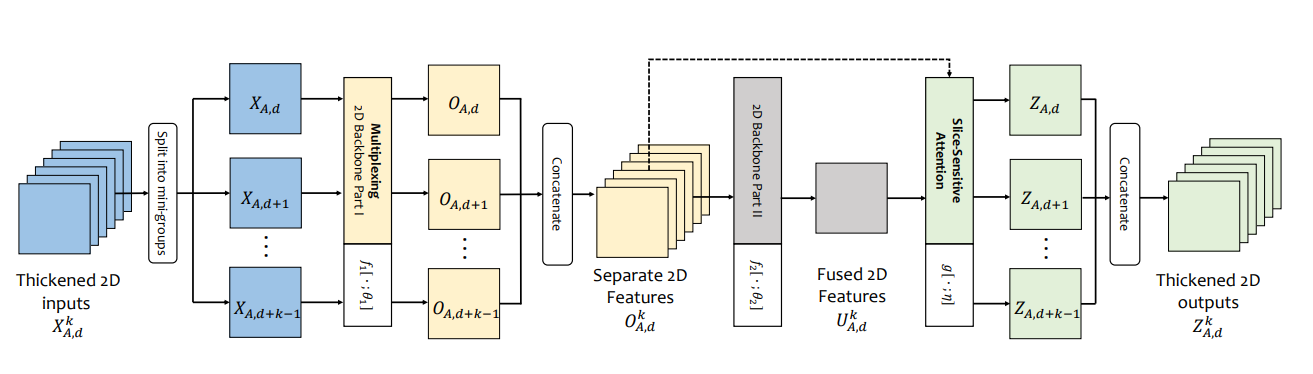
|
|

|
|
|
Stolen from Jon Barron |